Design in PostgreSQL, document-oriented API: Complex queries (Part 4)
document Storage in Postgres a bit easier, we now have serious of the stored procedure, the ability to run full text search, and some simple search and filter.
This is only half the story, of course. Rudimentary searches can serve the needs of the application, but they will never work in the long term, when we will have to ask more profound questions.
Storage of documents is a very big topic. How to store a document (and that store), for me, is divided into three areas:
the
I really tend to last. I information drive and when something happens, I want to know what/why/where, up to any limits.
That's what I did before to keep information about people who buy something at Tekpub. This format of the document that I was going to use but never got to this (with the sale on Plularsight).
the
This document. I love large documents! This document is an accurate result of all movements of information in the checkout process:
the
I want to document this was an Autonomous, self-sufficient object, which does not need any other documents to be completed. In other words, I would like to be able to:
the
This document is completed in itself and it's wonderful!
OK, enough, let's write some reports.
To summarize Analytics it is important to remember two things:
the
Execute a huge query on the combined table takes forever, and it leads to nothing in the end. You should create reports on historical data that does not change (or change very little) over time. Denormalization helps with speed, and speed is your friend when building reports.
Given this, we should use kindness PostgreSQL to generate our data in fact table sales. The "actual" table is simply a denormalized data set that represents the event in your system — the smallest amount of digestible information on fact.
For us, this fact — sales, and we want this event looked like this:

I use the Chinook sample database with some random sales data-created by Faker.
Each of these records is a single event that I want to accumulate, and the information about the dimension which I want to combine them (time, provider) is already included. I can add more (category etc.), but is enough for this.
These data are in tabular form, this means that we need to extract them from the document shown above. The task is not easy, but much easier since we use PostgreSQL:
the
This is a set of common table expressions (CTE), combined in a functional way (see below). If you've never used the TOB — they may look a bit unusual... until you look closely and do not realize that you just combine things together names.
In the first query above, I pull the id sales, calling it invoice_id, and then pull timestamp and converts it into timestampz, Simple steps in nature.
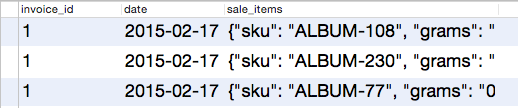
What is interesting here is jsonb_array_elements, which pulls an array of objects from the document and creates an entry for each of them. That is, if we had the basis of a single document with three objects and run the following query:
the
Instead of a single record representing a sale, we would have 3:
Now that we have allocated objects, we need to split them into separate columns. Here and there the next trick with the jsonb_to_record. We can use this function describing values of types on the fly:
the
In this simple example, I convert jsonb in a table I only need enough to tell PostgreSQL how to do it. This is exactly what we do in the second CTE ("event") above. Also, we use date_part to convert dates.
This gives us a table of events that we may keep in view if we:
the
You may think that this query is horribly slow. In fact, it is quite fast. This is not some kind of benchmark, or anything like that — just relative to show you that this query really fast. I have a 1000 test documents in the database, run this query on all documents returned in about a tenth of a second:

PostgreSQL. Really cool.
Now we are ready for some savings!
Then it gets easier. You simply gather the data you want, and if you're talking about forgetting something — just add it to your view and not have to worry about any unions of tables. Just a data conversion, which really is fast.
Let's look at the five best sellers:
the
This query returns data for 0.12 seconds. Fast enough for 1000 records.
One of the things that I really like RethinkDB it's its own query language, ReQL. It is inspired by Haskell (in accordance with the team) and the whole is the composition (especially for me):
As you can see above, we can approximate this using a CTE combined together, each of which converts information of a specific way.
There is so much more that I could write, but let's just summarize this all what you can do all that I can do other document-oriented systems and more.query Capabilities in Postgres are very great — there is a very small list of things you can't do and, as you saw, the option to convert Your document into a table structure is very helpful.
And this is the end of this little series.
Article based on information from habrahabr.ru
This is only half the story, of course. Rudimentary searches can serve the needs of the application, but they will never work in the long term, when we will have to ask more profound questions.
Source document
Storage of documents is a very big topic. How to store a document (and that store), for me, is divided into three areas:
the
- Real world. Invoices, purchase orders — business runs on these things — let's think about it. the
- Transaction, the results of the process, the event sources. In fact, when "something happens" with the app, you keep track of everything that happened at the same time and keep it.
the document Model and domain. Look at this from the developer, but if you're a fan of DDD(Domain Driven Design), it plays a role. the
I really tend to last. I information drive and when something happens, I want to know what/why/where, up to any limits.
That's what I did before to keep information about people who buy something at Tekpub. This format of the document that I was going to use but never got to this (with the sale on Plularsight).
the
{
"id": 1,
"items": [
{
"sku": "ALBUM-108",
"grams": "0",
"price": 1317,
"taxes": [],
"vendor": "Iron Maiden",
"taxable": true,
"quantity": 1,
"discounts": [],
"gift_card": false,
"fulfillment": "download",
"requires_shipping": false
}
],
"notes": [],
"source": "Web",
"status": "complete",
"payment": {
//...
},
"customer": {
//...
},
"referral": {
//...
},
"discounts": [],
"started_at": "2015-02-18T03:07:33.037 Z",
"completed_at": "2015-02-18T03:07:33.037 Z",
"billing_address": {
//...
},
"shipping_address": {
//...
},
"processor_response": {
//...
}
}
This document. I love large documents! This document is an accurate result of all movements of information in the checkout process:
the
-
the
- client Address (for billing, for shipping) the
- Payment info and it was purchased
- Precise response from the processor (which in itself is a large document)
How they got here and brief info about what happened on their way (in note form) the
I want to document this was an Autonomous, self-sufficient object, which does not need any other documents to be completed. In other words, I would like to be able to:
the
-
the
- to order the
- to Run some reports the
- to Inform the client about changes, performance, etc. the
- to Take further action if required (debit, cancel)
This document is completed in itself and it's wonderful!
OK, enough, let's write some reports.
shape data. The actual table
To summarize Analytics it is important to remember two things:
the
- denormalization is the norm
Never spend it on a running system the
Execute a huge query on the combined table takes forever, and it leads to nothing in the end. You should create reports on historical data that does not change (or change very little) over time. Denormalization helps with speed, and speed is your friend when building reports.
Given this, we should use kindness PostgreSQL to generate our data in fact table sales. The "actual" table is simply a denormalized data set that represents the event in your system — the smallest amount of digestible information on fact.
For us, this fact — sales, and we want this event looked like this:
I use the Chinook sample database with some random sales data-created by Faker.
Each of these records is a single event that I want to accumulate, and the information about the dimension which I want to combine them (time, provider) is already included. I can add more (category etc.), but is enough for this.
These data are in tabular form, this means that we need to extract them from the document shown above. The task is not easy, but much easier since we use PostgreSQL:
the
with items as (
select body -> 'id' as invoice_id,
(body ->> 'completed_at')::timestamptz as date,
jsonb_array_elements(body -> 'items') as sale_items
from sales
), fact as (
select invoice_id,
date_part('quarter', date) as quarter,
date_part('year', date) as year,
date_part('month', date) as month,
date_part('day', date) as day,
x.*
from items, jsonb_to_record(sale_items) as x(
sku varchar(50),
vendor varchar(255),
price int,
quantity int
)
)
select * from fact;
This is a set of common table expressions (CTE), combined in a functional way (see below). If you've never used the TOB — they may look a bit unusual... until you look closely and do not realize that you just combine things together names.
In the first query above, I pull the id sales, calling it invoice_id, and then pull timestamp and converts it into timestampz, Simple steps in nature.
What is interesting here is jsonb_array_elements, which pulls an array of objects from the document and creates an entry for each of them. That is, if we had the basis of a single document with three objects and run the following query:
the
select body -> 'id' as invoice_id,
(body ->> 'completed_at')::timestamptz as date,
jsonb_array_elements(body -> 'items') as sale_items
from sales
Instead of a single record representing a sale, we would have 3:
Now that we have allocated objects, we need to split them into separate columns. Here and there the next trick with the jsonb_to_record. We can use this function describing values of types on the fly:
the
select * from jsonb_to_record(
'{"name" : "Rob", "occupation": "Hazard"}'
) as (
name varchar(50),
occupation varchar(255)
)
In this simple example, I convert jsonb in a table I only need enough to tell PostgreSQL how to do it. This is exactly what we do in the second CTE ("event") above. Also, we use date_part to convert dates.
This gives us a table of events that we may keep in view if we:
the
create view sales_fact as
-- the query above
You may think that this query is horribly slow. In fact, it is quite fast. This is not some kind of benchmark, or anything like that — just relative to show you that this query really fast. I have a 1000 test documents in the database, run this query on all documents returned in about a tenth of a second:
PostgreSQL. Really cool.
Now we are ready for some savings!
sales Report
Then it gets easier. You simply gather the data you want, and if you're talking about forgetting something — just add it to your view and not have to worry about any unions of tables. Just a data conversion, which really is fast.
Let's look at the five best sellers:
the
select sku,
sum(quantity) as sales_count,
sum((price * quantity)/100)::money as sales_total
from sales_fact
group by sku
order by salesCount desc
limit 5
This query returns data for 0.12 seconds. Fast enough for 1000 records.
RESP and feature requests
One of the things that I really like RethinkDB it's its own query language, ReQL. It is inspired by Haskell (in accordance with the team) and the whole is the composition (especially for me):
to understand ReQL, it helps to understand functional programming. Functional programming is included in the declarative paradigm in which the programmer seeks to describe the value he wants to calculate, rather than describe the steps required to calculate this value. Query languages of databases, as a rule, aspires to the declarative ideal that this gives the query processor the most freedom in selecting the optimal execution plan. But while SQL achieves this using special keywords and a specific declarative syntax, ReQL has the ability to Express arbitrarily complex operations through functional composition.
As you can see above, we can approximate this using a CTE combined together, each of which converts information of a specific way.
Opinion
There is so much more that I could write, but let's just summarize this all what you can do all that I can do other document-oriented systems and more.query Capabilities in Postgres are very great — there is a very small list of things you can't do and, as you saw, the option to convert Your document into a table structure is very helpful.
And this is the end of this little series.



Комментарии
Отправить комментарий