The best publication in social networks
Hello. In my free time I am engaged in social projects. I and my friends have a sufficient number of "pages" in different social networks that allows us to conduct various experiments. Acute issue of finding relevant content and news that you can publish. In connection with this, came the idea to write a service that will collect posts of the most popular pages and give them with the specified filter. For the initial test, chose the social network Vkontakte and Twitter.
First, it was necessary to identify data store (by the way, now the number of saved more than 2 million) and this figure will melt away every day. The requirements were: very often insert large amounts of data and quick selection among them.
Already heard about nosql databases and wanted to try them. I will not describe the article comparison of bases, which I spent (mysql vs sqlite vs mongodb).
As caching has chosen memcached, later will explain why and in which cases.
As a data collector was written in python daemon, which updates in parallel all groups from the database.
First, I wrote a prototype collector publications of the groups. Saw a few problems:
the
One publication with all metadata takes about 5-6KB of data, and in the middle group of about 20,000-30,000 records, turns out about 175МБ data on one group, and these groups very much. So I had to put the task in the filtering of uninteresting and advertising publications.
Too many to invent did not have, I only have 2 "tables": groups and posts, the first keeps a record of the groups that need to parse and update, and the second scope all publications of all groups. Now I think it's unnecessary and even a bad decision. It would be best to create a table for each group can be fetched and sorting records, although the rate of even 2 million is not lost. But such an approach should simplify the overall sample for all groups.
In cases where you need server-side processing of some data from the social network Vkontakte, created a standalone application that can issue a token to any action. For such cases, I have saved the note with that address:
Instead of APP_ID insert the ID of your standalone application. Generated token allows at any time to apply to the specified action.
The algorithm of the parser is:
Take the group id, in the loop obtained all publications for each iteration produced a filtration of "bad" posts that are saved to the database.
The main problem is speed. Vkontakte API allows you to perform 3 requests per second. 1 a query can retrieve a total of 100 publications 300 publications per second.
In the case a parser is not so bad: you can "merge" in one minute, but the update will have problems. The more groups, the longer will be the upgrade and, accordingly, the results will not be so quickly updated.
The output was the use of the execute method that allows to gather the api requests and execute a bunch at a time. So I in a single query doing 5 iterations and get 500 publications — 1500 per second, which gives the "drain" of the group for ~13 seconds.
Here is the code file that is passed to execute:
the
Code is read into memory, the token replacement is done replace_group_id and replace_start_offset. The result is an array of publications, which you can see on the official page VK API vk.com/dev/wall.get
The next stage filter. I took different groups, viewed the publication and come up with possible options for screening. First decided to delete all posts with links to external pages. Almost always it is.
the
Then decided to completely eliminate reposts is 99% advertising. Few will just do a repost of someone else's page. To check for a repost is very simple:
the
item — another element from the collection of walls which returned to the execute method.
Also noticed that a lot of ancient publications are empty, they have no attachments, and the text is empty. Filter enough that proelite item['attachments'] and item['text'] is empty.
And the last filter that I just put over time:
the
As in the previous paragraph, a lot of old publications with text (description of the picture in the attachment), but the pictures have not survived.
The next step was cleanup failed publications that are simply "not logged in":
the
This method is executed on a posts table that has a field likes (number of likes from posts). It returns the arithmetic mean of likes for this group.
Now you can simply delete all posts older than 3 days, which is less than the average number of likes:
the
the
The resulting filtered and the publication is added to the database, the parsing ends. The difference between parsing and updating the groups I made only one point: the upgrade is invoked exactly 1 time for the group, i.e. receive only the 500 most recent posts (5 at 100 using execute). In General this is sufficient, given that Vkontakte has introduced a limit on the number of publications: 200 per day.
I am not going to discuss in detail, javascript + jquery + isotope + inview + mustache.
the
To output the data groups were written a simple php script.
This is a helper function, which filter type time created object, which you can use directly in the query.
the
And the following code gets the 15 best posts of the month:
the
View statistics for group interesting, but more interesting to build a General rating of all groups and their publications. If you think about it, a very difficult job:
We can build only on 3 factors: the number of likes, reposts and subscribers. The more subscribers the more likes and reposts, but it does not guarantee the quality of the content.
Most of the groups reviewed, and often publish trash that is already a few years wandering the Internet, and millions of subscribers are always those who will repost and like.
To build a rating of the bare figures easily, but the result can not be called a ranking of publications by their quality and uniqueness.
The idea was to deduce the quality factor of each group: to build the timeline, watch the activity of users for each period of time and so on.
Unfortunately, an adequate solution I came up with. If you have any ideas, I will be glad to listen.
The first thing I realized was the realization that the contents of the index pages need to calculate and cache for all users because it is a very slow operation. Here comes to the aid of memcached. The simple logic has been selected the following algorithm:
As a result, the results from one group will not be more than 2 publications. Of course, this is not the correct result, but in practice shows good statistics and the relevance of the content.
Here is the code of a thread that every 15 minutes generates an index page:
the
Describe filters that affect the results:
Time: hour, day, week, month, year, all the time
Type: like, repost, comments
For all time points was generated objects
the
They all passed to the function _get along with different variations of filter by type (likes, reposts, comments). More to all this, you need to generate 5 pages for every variation of filters. As a result, in memcached are put down the following keys:
And on the client side is generated only need the key and pulled out a json string from memcached.
Twitter
Next interesting task was to generate popular tweets for the CIS. The task is too difficult, I would like to get relevant and not "treshovy" information. I was surprised by the restrictions of Twitter: do not get so just go and merge all the tweets for specific users. The API limits the number of queries, so it is impossible to do as it makes the VC to make a list of popular accounts and constantly parse their tweets.
Through the day, it's the solution: create a Twitter account, subscribe to all the important people, the subject of publications which are of interest to us. The trick is that almost 80% of cases, some of these people do retweet some popular tweets. Ie we don't need to have in the database a list of all accounts, enough to gain a base of 500-600 active people who are constantly in trend and make retweets really interesting and popular tweets.
In the Twitter API has a method that allows to obtain a user's feed, which includes tweets those whom we signed them and repost. All we need now is 10 minutes to read the maximum our band, and keep the tweets, filters, and everything else is left the same as in the case with Facebook.
So, was written by another thread within the demon that once in 10 minutes, run this code:
the
Well, after the usual and boring code we have tweetList, go through a loop and process each tweet. The field list in the official documentation. The only thing I would like to focus:
the
In the case of the retweet, we need to save a tweet from one of our subscribers, and original. If the current entry is a retweet, it contains the key 'retweeted_status' is exactly the same the object of the tweet, only the original.
Your site's design and layout has issues (I myself am never a web programmer), but I hope someone will be useful information that I described. He is already a lot of time working with social services. networks and their APIs, and I know a lot of tricks. If someone have any questions I will be glad to help.
Well, a few pictures:

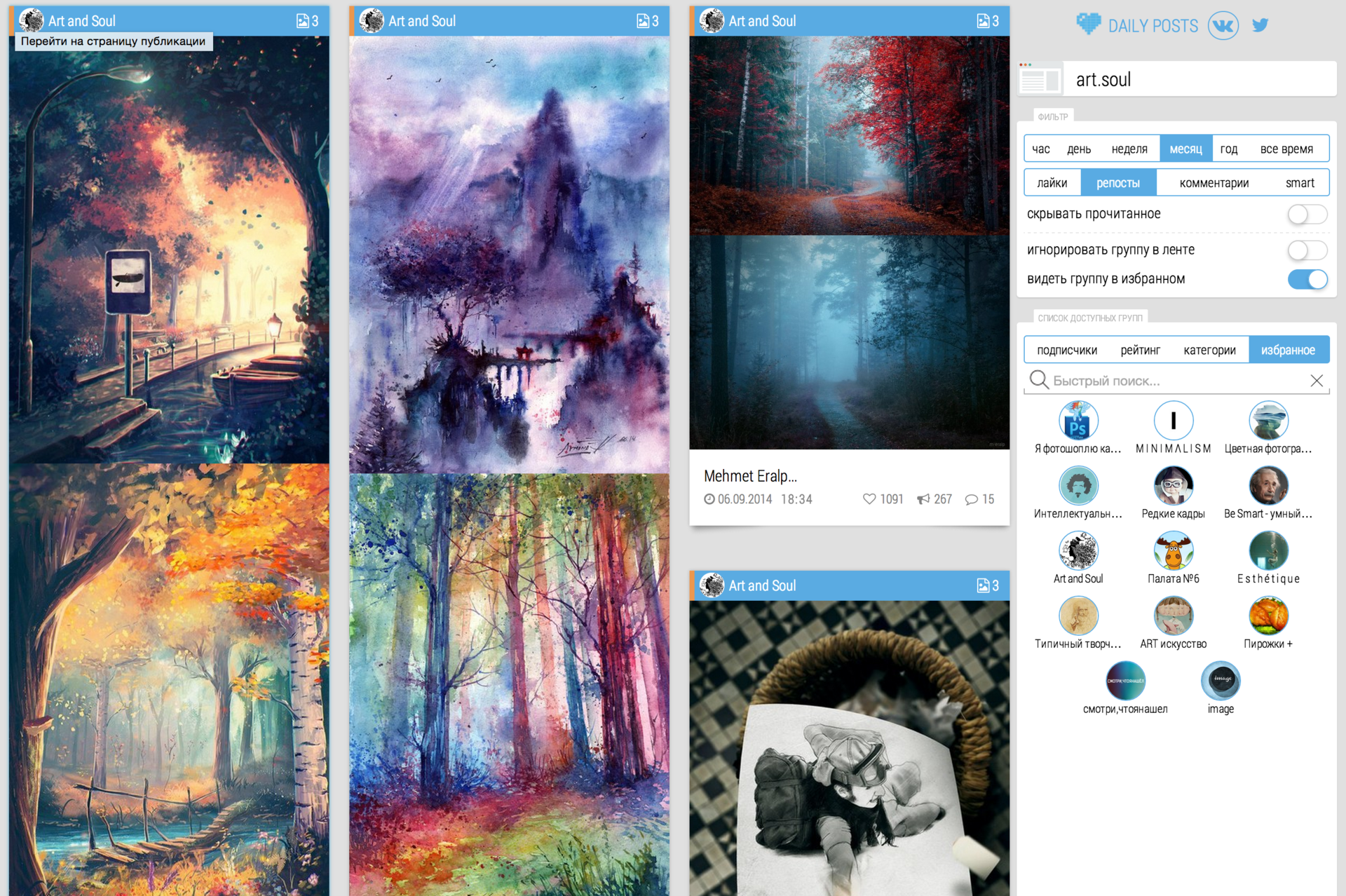
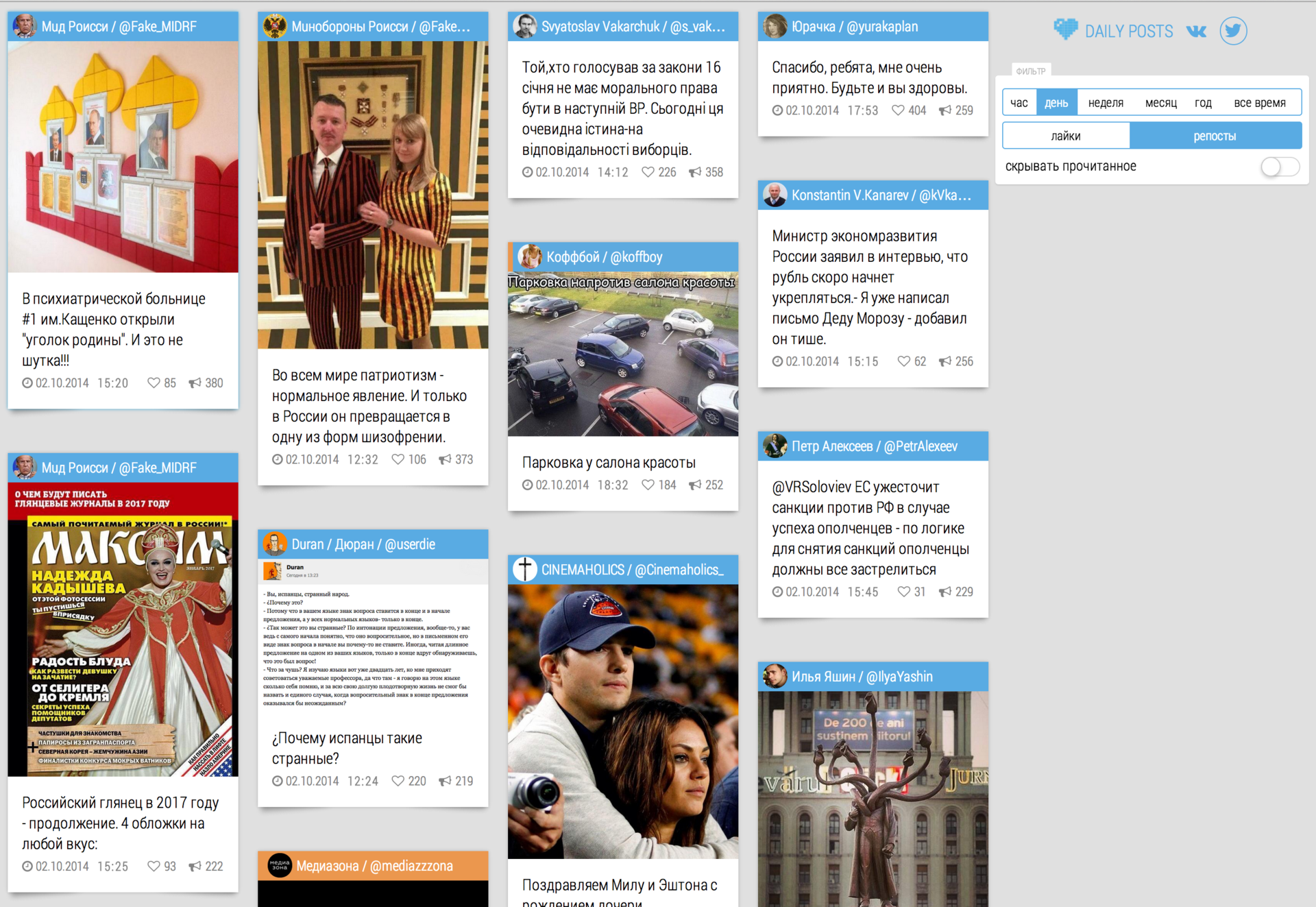
Thank you for your attention.
 — 88.198.106.150
— 88.198.106.150
Article based on information from habrahabr.ru
Technology
First, it was necessary to identify data store (by the way, now the number of saved more than 2 million) and this figure will melt away every day. The requirements were: very often insert large amounts of data and quick selection among them.
Already heard about nosql databases and wanted to try them. I will not describe the article comparison of bases, which I spent (mysql vs sqlite vs mongodb).
As caching has chosen memcached, later will explain why and in which cases.
As a data collector was written in python daemon, which updates in parallel all groups from the database.
MongoDB daemon
First, I wrote a prototype collector publications of the groups. Saw a few problems:
the
-
the
- storage capacity the
- API Limits
One publication with all metadata takes about 5-6KB of data, and in the middle group of about 20,000-30,000 records, turns out about 175МБ data on one group, and these groups very much. So I had to put the task in the filtering of uninteresting and advertising publications.
Too many to invent did not have, I only have 2 "tables": groups and posts, the first keeps a record of the groups that need to parse and update, and the second scope all publications of all groups. Now I think it's unnecessary and even a bad decision. It would be best to create a table for each group can be fetched and sorting records, although the rate of even 2 million is not lost. But such an approach should simplify the overall sample for all groups.
API
In cases where you need server-side processing of some data from the social network Vkontakte, created a standalone application that can issue a token to any action. For such cases, I have saved the note with that address:
oauth.vk.com/authorize?client_id=APP_ID&redirect_uri=https://oauth.vk.com/blank.html&response_type=token&scope=groups,offline,photos,friends,wall
Instead of APP_ID insert the ID of your standalone application. Generated token allows at any time to apply to the specified action.
The algorithm of the parser is:
Take the group id, in the loop obtained all publications for each iteration produced a filtration of "bad" posts that are saved to the database.
The main problem is speed. Vkontakte API allows you to perform 3 requests per second. 1 a query can retrieve a total of 100 publications 300 publications per second.
In the case a parser is not so bad: you can "merge" in one minute, but the update will have problems. The more groups, the longer will be the upgrade and, accordingly, the results will not be so quickly updated.
The output was the use of the execute method that allows to gather the api requests and execute a bunch at a time. So I in a single query doing 5 iterations and get 500 publications — 1500 per second, which gives the "drain" of the group for ~13 seconds.
Here is the code file that is passed to execute:
the
var groupId = -|replace_group_id|;
var startOffset = |replace_start_offset|;
var it = 0;
var offset = 0;
var walls = [];
while(it < 5)
{
var count = 100;
offset = startOffset + it * count;
walls = walls + [API.wall.get({"owner_id": groupId, "count" : count, offset : offset})];
it = it + 1;
}
return
{
"offset" : offset,
"walls" : walls
};
Code is read into memory, the token replacement is done replace_group_id and replace_start_offset. The result is an array of publications, which you can see on the official page VK API vk.com/dev/wall.get
The next stage filter. I took different groups, viewed the publication and come up with possible options for screening. First decided to delete all posts with links to external pages. Almost always it is.
the
urls1 = re.findall('http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', text)
urls2 = re.findall(ur"[-a-zA-Z0-9@:%._\+~#=]{2,256}\.[a-z]{2,6}\b([-a-zA-Z0-9@:%_\+.~#?&& //=]*) ", text)
or if urls1 urls2:
# To ignore this publication
Then decided to completely eliminate reposts is 99% advertising. Few will just do a repost of someone else's page. To check for a repost is very simple:
the
if item['post_type'] == 'copy':
return Falseitem — another element from the collection of walls which returned to the execute method.
Also noticed that a lot of ancient publications are empty, they have no attachments, and the text is empty. Filter enough that proelite item['attachments'] and item['text'] is empty.
And the last filter that I just put over time:
the
yearAgo = datetime.datetime.now() - datetime.timedelta(days=200)
createTime = datetime.datetime.fromtimestamp(int(item['date']))
if createTime <= yearAgo and not attachments and len(text) < 75:
# Ignore this postAs in the previous paragraph, a lot of old publications with text (description of the picture in the attachment), but the pictures have not survived.
The next step was cleanup failed publications that are simply "not logged in":
the
db.posts.aggregate(
{
$match : { gid : GROUP_ID }
},
{
$group : { _id : "$gid", average : {$avg : "$likes"} }
}
)
This method is executed on a posts table that has a field likes (number of likes from posts). It returns the arithmetic mean of likes for this group.
Now you can simply delete all posts older than 3 days, which is less than the average number of likes:
the
db.posts.remove(
{
gid : groupId,
'created' : { '$lt' : removeTime },
'likes': { '$lt' : avg }
}
)the
removeTime = datetime.datetime.now() - datetime.timedelta(days=3)
avg = the result of the previous query is divided into two (brute force).
The resulting filtered and the publication is added to the database, the parsing ends. The difference between parsing and updating the groups I made only one point: the upgrade is invoked exactly 1 time for the group, i.e. receive only the 500 most recent posts (5 at 100 using execute). In General this is sufficient, given that Vkontakte has introduced a limit on the number of publications: 200 per day.
Front-end
I am not going to discuss in detail, javascript + jquery + isotope + inview + mustache.
the
-
the
- Isotope used for current output of publications in the form of tiles. the
- Inview makes it easy to respond to events falling in the viewport opredelennogo element. (in my case — remember reviewed publications, and a new allocate special color). the
- Mustache allows you to build dom-objects in the template.
Filter articles by group
To output the data groups were written a simple php script.
This is a helper function, which filter type time created object, which you can use directly in the query.
the
function filterToTime($timeFilter)
{
$mongotime = null;
if ($timeFilter == 'year')
$mongotime = new Mongodate(strtotime("-1 year", time()));
else if ($timeFilter == 'month')
$mongotime = new Mongodate(strtotime("-1 month", time()));
else if ($timeFilter == 'week')
$mongotime = new Mongodate(strtotime("-1 week", time()));
else if ($timeFilter == 'day')
$mongotime = new Mongodate(strtotime("midnight"));
else if ($timeFilter == 'hour')
$mongotime = new Mongodate(strtotime("-1 hour"));
return $mongotime;
}
And the following code gets the 15 best posts of the month:
the
$groupId = 42; // Some id of the group
$mongotime = filterToTime('week');
$offset = 1; // First page
$findCondition = array('gid' = > $groupId, 'created' => array('$gt' => $mongotime));
$mongoHandle->posts->find($findCondition)- > limit(15)- > skip($offset * $numPosts);
Logic index page
View statistics for group interesting, but more interesting to build a General rating of all groups and their publications. If you think about it, a very difficult job:
We can build only on 3 factors: the number of likes, reposts and subscribers. The more subscribers the more likes and reposts, but it does not guarantee the quality of the content.
Most of the groups reviewed, and often publish trash that is already a few years wandering the Internet, and millions of subscribers are always those who will repost and like.
To build a rating of the bare figures easily, but the result can not be called a ranking of publications by their quality and uniqueness.
The idea was to deduce the quality factor of each group: to build the timeline, watch the activity of users for each period of time and so on.
Unfortunately, an adequate solution I came up with. If you have any ideas, I will be glad to listen.
The first thing I realized was the realization that the contents of the index pages need to calculate and cache for all users because it is a very slow operation. Here comes to the aid of memcached. The simple logic has been selected the following algorithm:
-
the
- Pass the loop over all groups the
- Take all the publications of the i-th group and choose 2 of them for a specified period of time
As a result, the results from one group will not be more than 2 publications. Of course, this is not the correct result, but in practice shows good statistics and the relevance of the content.
Here is the code of a thread that every 15 minutes generates an index page:
the
# timeDelta - type filter time (hour, day, week, year, alltime)
# filterType - likes, reposts, comments
# deep - 0, 1, ... (page)
def _get(self, timeDelta, filterTime, filterType='likes', deep = 0):
groupList = groups.find({}, {'_id' : 0})
allPosts = []
allGroups = []
for group in groupList:
allGroups.append(group)
postList = db['posts'].find({'gid' : group['id'], 'created' : {'$gt' : timeDelta}}) \
.sort(filterType, -1).skip(deep * 2).limit(2)
for post in postList:
allPosts.append(post)
result = {
'posts' : allPosts[:50],
'groups' : allGroups
}
# This code allows to generate a timestamp from the mongotime, when converting to json
dthandler = lambda obj: (time.mktime(obj.timetuple()) if isinstance(obj, datetime.datetime) or isinstance(obj, datetime.date) else None)
jsonResult = json.dumps(result, default=dthandler)
key = 'index_' +filterTime+ '_' +filterType+ '_' + str(deep)
print 'Setting key: ',
print key
self.memcacheHandle.set(key, jsonResult)
Describe filters that affect the results:
Time: hour, day, week, month, year, all the time
Type: like, repost, comments
For all time points was generated objects
the
hourAgo = datetime.datetime.now() - datetime.timedelta(hours=3)
midnight = datetime.datetime.now().replace(hour=0, minute=0, second=0, microsecond=0)
weekAgo = datetime.datetime.now() - datetime.timedelta(weeks=1)
monthAgo = datetime.datetime.now() + dateutil.relativedelta.relativedelta(months=-1)
yearAgo = datetime.datetime.now() + dateutil.relativedelta.relativedelta(years=-1)
alltimeAgo = datetime.datetime.now() + dateutil.relativedelta.relativedelta(years=-10)
They all passed to the function _get along with different variations of filter by type (likes, reposts, comments). More to all this, you need to generate 5 pages for every variation of filters. As a result, in memcached are put down the following keys:
Setting key: index_hour_likes_0
Setting key: index_hour_reposts_0
Setting key: index_hour_comments_0
Setting key: index_hour_common_0
Setting key: index_hour_likes_1
Setting key: index_hour_reposts_1
Setting key: index_hour_comments_1
Setting key: index_hour_common_1
Setting key: index_hour_likes_2
Setting key: index_hour_reposts_2
Setting key: index_hour_comments_2
Setting key: index_hour_common_2
Setting key: index_hour_likes_3
Setting key: index_hour_reposts_3
Setting key: index_hour_comments_3
Setting key: index_hour_common_3
Setting key: index_hour_likes_4
Setting key: index_hour_reposts_4
Setting key: index_hour_comments_4
Setting key: index_hour_common_4
Setting key: index_day_likes_0
Setting key: index_day_reposts_0
Setting key: index_day_comments_0
Setting key: index_day_common_0
Setting key: index_day_likes_1
Setting key: index_day_reposts_1
Setting key: index_day_comments_1
Setting key: index_day_common_1
Setting key: index_day_likes_2
Setting key: index_day_reposts_2
Setting key: index_day_comments_2
Setting key: index_day_common_2
Setting key: index_day_likes_3
Setting key: index_day_reposts_3
...
And on the client side is generated only need the key and pulled out a json string from memcached.
Next interesting task was to generate popular tweets for the CIS. The task is too difficult, I would like to get relevant and not "treshovy" information. I was surprised by the restrictions of Twitter: do not get so just go and merge all the tweets for specific users. The API limits the number of queries, so it is impossible to do as it makes the VC to make a list of popular accounts and constantly parse their tweets.
Through the day, it's the solution: create a Twitter account, subscribe to all the important people, the subject of publications which are of interest to us. The trick is that almost 80% of cases, some of these people do retweet some popular tweets. Ie we don't need to have in the database a list of all accounts, enough to gain a base of 500-600 active people who are constantly in trend and make retweets really interesting and popular tweets.
In the Twitter API has a method that allows to obtain a user's feed, which includes tweets those whom we signed them and repost. All we need now is 10 minutes to read the maximum our band, and keep the tweets, filters, and everything else is left the same as in the case with Facebook.
So, was written by another thread within the demon that once in 10 minutes, run this code:
the
def __init__(self):
self.twitter = Twython(APP_KEY, APP_SECRET, TOKEN, TOKEN_SECRET)
def logic(self):
lastTweetId = 0
for i in xrange(15): # Figure chosen at random
self.getLimits()
tweetList = []
if i == 0:
tweetList = self.twitter.get_home_timeline(count=200)
else:
tweetList = self.twitter.get_home_timeline(count=200, max_id=lastTweetId)
if len(tweetList) <= 1:
print '1 tweet breaking' # All, more tweets API, we will not give
break
# ...
lastTweetId = tweetList[len(tweetList)-1]['id']
Well, after the usual and boring code we have tweetList, go through a loop and process each tweet. The field list in the official documentation. The only thing I would like to focus:
the
for tweet in tweetList:
localData = None
if 'retweeted_status' in tweet:
localData = tweet['retweeted_status']
else:
localData = tweet
In the case of the retweet, we need to save a tweet from one of our subscribers, and original. If the current entry is a retweet, it contains the key 'retweeted_status' is exactly the same the object of the tweet, only the original.
Final
Your site's design and layout has issues (I myself am never a web programmer), but I hope someone will be useful information that I described. He is already a lot of time working with social services. networks and their APIs, and I know a lot of tricks. If someone have any questions I will be glad to help.
Well, a few pictures:
Index-page:

Page one of the groups that I constantly monitor:

Twitter per day:

Thank you for your attention.
 — 88.198.106.150
— 88.198.106.150


Комментарии
Отправить комментарий